

Hey, fantastic readers, I hope you’re all doing great!
In my previous blog on classification in supervised learning, I discussed classification and applications of classification, key components of classification, popular classification algorithms, interpretability techniques, and potential biases and limitations in classifier decisions.
Building upon that foundation, I am excited to continue our exploration by focusing specifically on decision trees. Decision trees, a machine learning technique, have proven to be a valuable tool for classification problems. Decision trees can handle large and complex data sets, provide predictions that are easy to interpret, and are flexible enough to handle a variety of data types.
Explanation of Classification Problems
Classification problems involve predicting an output or a class label for a data point based on the input features. In essence, classifying data involves dividing data points into pre-defined categories. The goal of any classification technique is to accurately assign class labels to new data points.
Importance of Decision Trees as a Classification Tool
Decision trees are an essential classification tool because they can handle both categorical and continuous input variables. They are also easy to interpret and understand, making them a popular choice for decision-makers who want actionable insights. Furthermore, decision trees can use minimal pre-processing, making them more cost and time-efficient.
Understanding Decision Trees
Explanation of Decision Trees
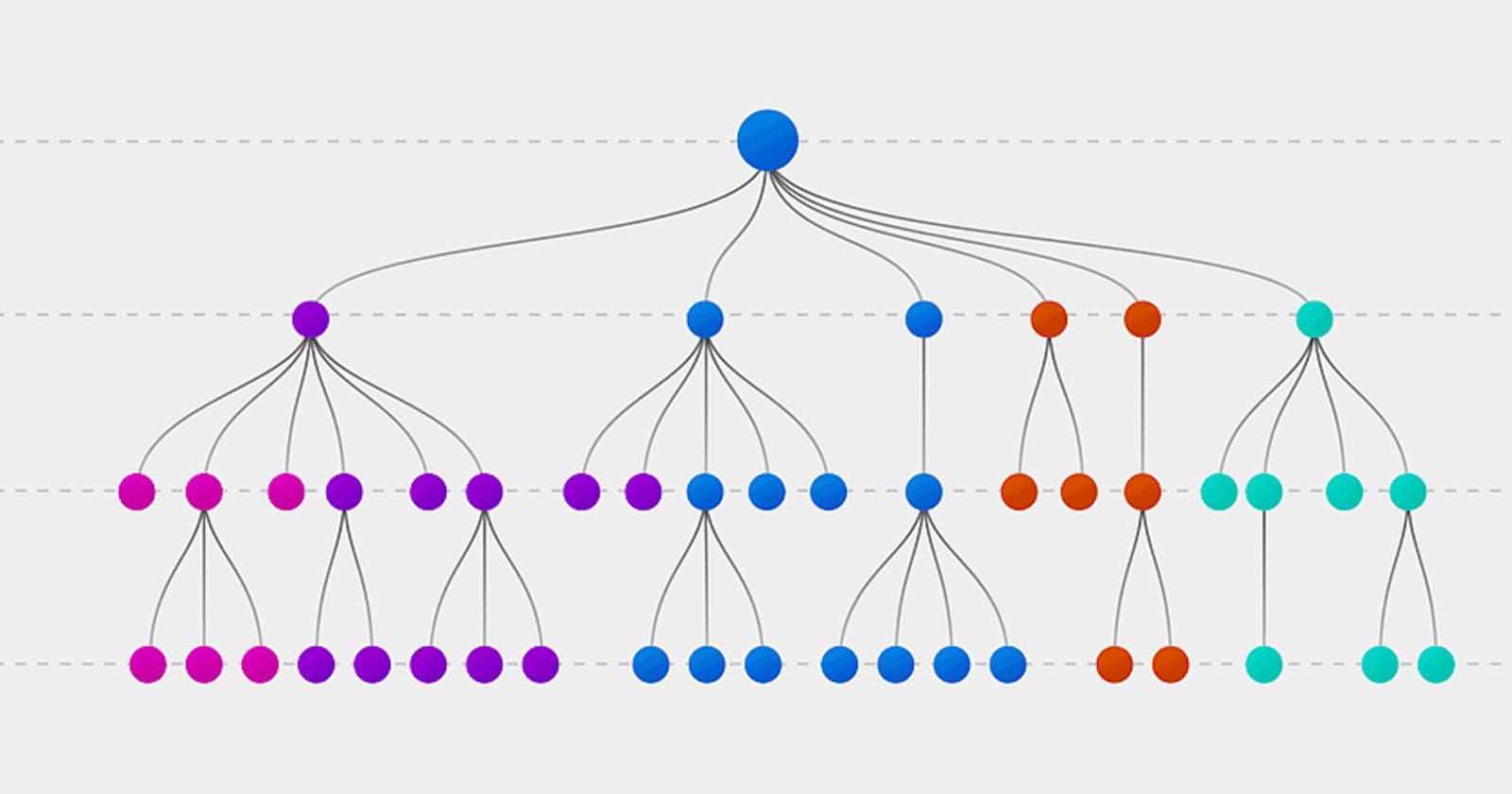
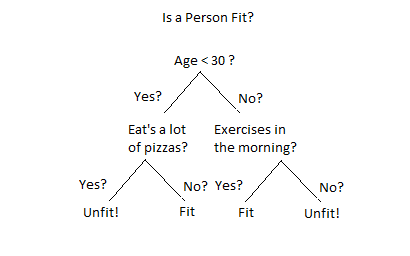
Decision trees are a machine learning algorithm that models decisions and decision-making. Decision tree models represent decisions and their possible consequences in a tree-like structure. Each internal node represents a test on an attribute or feature, each branch represents the outcome of the test, and each leaf node represents a class label.
Components of a Decision Tree
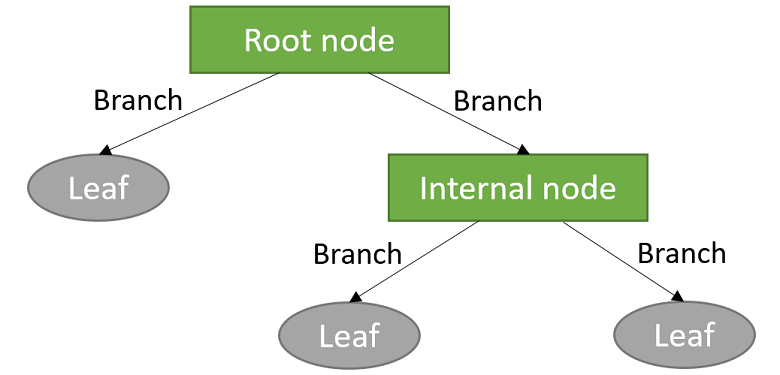
Root node: It is the first node of the tree.
Internal node: Nodes that have one or more child nodes.
Leaf node: Nodes that have no child nodes.
Splitting rules: The criteria used to decide how to split data at each internal node.
Decision rules: A set of guided decisions that will bring the user to the correct group.
Branches: The sequence of decisions that lead from the root to a leaf node.
Types of Decision Trees
There are two types of decision trees:
Classification Trees: Used for categorical input variables and classify input variables into groups or labels.
Regression Trees: Used for continuous input variables, where the output is a continuous variable or real number.
Data Preparation
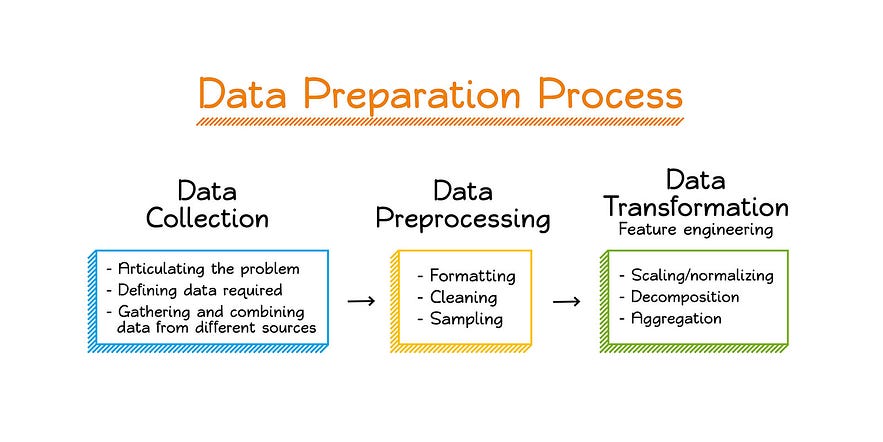
Importance of Clean and Relevant Data
Clean and relevant data is critical to building accurate decision trees. Data that is not cleaned and pre-processed can adversely affect the performance of a model and generate poor predictions.
Data Exploration Techniques
Data exploration techniques include visualization and statistical tools to understand the distribution of input variables and their relationships with the output variable. This exploration can provide insights into the critical features required to build optimal decision trees.
Data Cleaning Techniques
Data cleaning techniques involve removing duplicate, incomplete, and noisy records or variables. These processes are useful for removing irrelevant features in the data set and enhancing the performance and accuracy of the decision tree model.
Data Transformation Techniques
Data transformation techniques include feature scaling, discretization, and normalization. Feature scaling is used to scale input variables. Discretization is the process of transforming continuous variables into categorical variables, and normalization is used to scale variables to specific ranges.
Building a Decision Tree
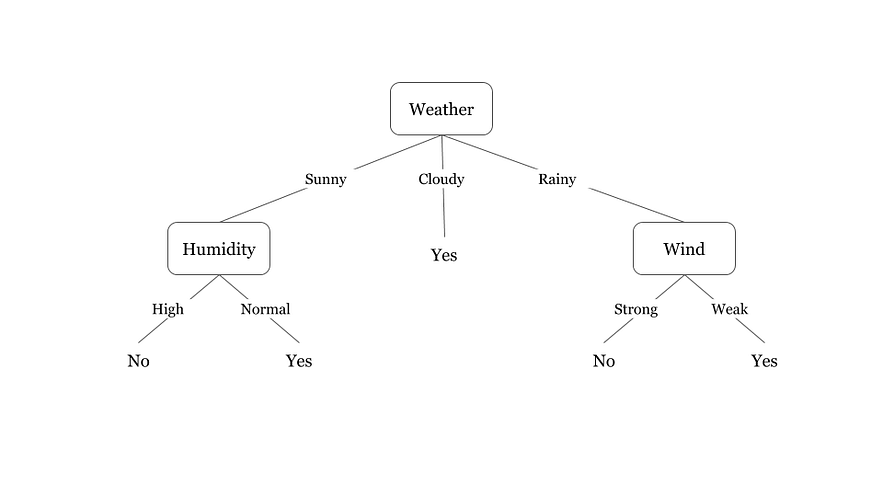
Decision Tree Learning Algorithms
There are several algorithms used to build decision trees, including the ID3, C4.5, and CART algorithms. The ID3 algorithm is used for categorical data, whereas the C4.5 and CART algorithms can handle both categorical and continuous data.
Common Splitting Criteria
Splitting criteria are used to determine the best way to partition data. Common splitting criteria include the Gini impurity index and information gain/entropy.
Techniques for Handling Missing Data
Handling missing values or data is essential for accurate decision tree modeling. Common techniques include using statistical tools such as mean, median, or mode imputation or removing entirely missing records.
Evaluating a Decision Tree
Techniques for Evaluating Decision Trees
Evaluation techniques involve measuring the accuracy, precision, and recall of the model. Common techniques include K-fold cross-validation, which randomly divides the data into subsets and trains the model on some subsets, then tests it on the other subset.
Gini Impurity vs Entropy
Gini impurity measures the probability of a randomly selected data point being misclassified, whereas entropy or information gain measures the reduction in uncertainty of the data set by introducing a new feature or test.
Overfitting and Underfitting
Overfitting and underfitting are common problems in decision tree modeling. Overfitting occurs when the model is too complex and fits the training data too closely, whereas underfitting is when the model is too simple and misses essential features in the data set.
Techniques for Improving Decision Trees
Techniques for improving decision tree performance and reducing overfitting include pruning, setting a minimum node size, setting a maximum tree depth, and using ensemble methods.
Advanced Decision Trees
Ensemble Methods
Ensemble methods involve combining several decision trees to produce an aggregate prediction. Two popular ensemble methods are random forests and boosting.
Random Forests
Random forests involve combining several decision trees by bootstrapping (sampling with replacement) and feature subsetting. This technique improves the accuracy of the model and reduces overfitting.
Boosting
Boosting involves combining several decision trees to improve the accuracy and performance of a model. Boosting algorithms sequentially build decision tree models that focus on the data points previously identified as difficult or misclassified.
Decision Trees in Real-World Applications

Industries and Sectors that Use Decision Trees
Decision trees are used in finance, healthcare, marketing, and science regularly. In finance, they are used to predict stock trends, and in healthcare, they are used to develop decision support systems in the diagnosis and management of diseases.
Examples of Decision Trees in Use
A common example of decision trees in use is in customer segmentation in e-commerce. By using decision trees, businesses can categorize customers based on their buying behavior, demographics, or patterns of interaction with the website.
Advantages and Disadvantages of Decision Trees
Benefits of Using Decision Trees
Decision trees offer several benefits such as:
Easy to interpret and understand.
Low error rates compared to other classification techniques.
Ability to handle both categorical and continuous input variables.
Drawbacks of Using Decision Trees
Drawbacks of using decision trees include:
Unstable decision trees due to changes in the data set
High sensitivity to noise in input data
Tendency to overfit if not pruned.
Decision Trees vs Other Classification Techniques

Comparison to Other Predictive Models
Decision trees have several advantages over alternative classification techniques such as logistic regression, naïve Bayes, and support vector machines. Decision trees can handle a more significant amount of data with interactions between input variables, making them more powerful for real-world problems.
When Decision Trees Are a Better Choice
Decision trees should be used when the data set is heterogeneous, features are categorical or continuous, and when the user requires quick and understandable results.
Handling Imbalanced Datasets

Explanation of Imbalanced Datasets
Imbalanced datasets occur when the ratio of one class to another is significant. Decision trees can result in a bias towards the majority class in such cases.
Techniques for Handling Imbalanced Data Using Decision Trees
Techniques for handling imbalanced data include oversampling, undersampling, and creating new trees that focus more on the minority class or using ensemble methods.
Tips for Proper Decision Tree Use
Best Practices for Using Decision Trees
Best practices entail simplifying decision trees, pruning, avoiding overfitting, cleaning the data set, and validating the accuracy and effectiveness of the model.
Pitfalls to Avoid
Pitfalls to avoid include overfitting, using poor-quality data sets, ignoring pruning, and not validating model results.
Interpretability of Decision Trees
How Decision Trees Are Easily Interpretable
Decision trees are easily interpretable due to their intuitive and easy-to-understand structure, making them an excellent option for decision-makers who prefer actionable insights.
Use Case Examples that Exhibit Interpretability
Interpretability is critical for decision-makers. Examples of decision trees in use include medical diagnoses for certain ailments or problems, which the doctors can explain to the patients and help them understand the diagnosis and the reasoning behind the treatment recommendations made.
The Future of Decision Trees

Recent Advancements in Decision Tree Technology
Recent advancements in decision tree technology include improving the scalability of decision trees, handling more extensive and high-dimensional data effectively, and improving prediction accuracy.
New Research and Development
New research and development are focused on improving the performance of decision trees, developing more accurate attributes for better classification and prediction, and exploring more advanced ensemble methods.
Conclusion
In conclusion, decision trees are a powerful classification tool that can effectively handle large and complex data sets, generate easy-to-interpret predictions, and are cost and time-efficient. Decision trees remain relevant in modern-day problems and will continue to evolve with cutting-edge research and development. Understanding the importance of decision trees and applying best practices can help businesses gain a competitive advantage and make more informed decisions.