Unmasking the Classifiers: Classification in Supervised Learning
Resuming the Quest: A Return to Knowledge Sharing



Yo, fantastic readers, I hope you’re all doing amazing! It’s been a while, and I appreciate your patience and am thrilled to reconnect with you.
In my previous blog post, I discussed Supervised learning, types of Supervised learning problems, algorithms used in Supervised learning, and advantages and disadvantages of Supervised learning. In this blog post, We’ll discuss the classification, one of the supervised learning problems, and how classification algorithms revolutionize our lives. So, join me on this exhilarating journey into the heart of supervised learning, where data meets intelligence and possibilities abound.
Understanding Classification: The Basics Unveiled
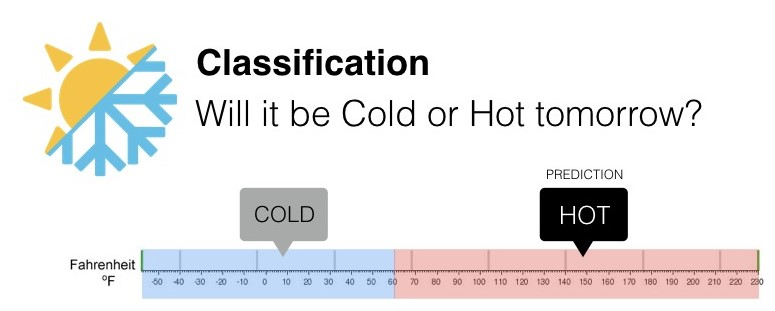
Classification is a type of supervised learning problem where the goal is to predict a categorical variable, such as a binary (yes/no) outcome or a multi-class outcome. For example, we use classification to predict if it is going to be hot or cold tomorrow(multi-class outcome).
Importance and Applications of Classification
The applications of classification are far-reaching and diverse. From spam email filtering to sentiment analysis in social media, classification helps automate tasks and streamline decision-making processes.
By harnessing the power of classification, organizations can enhance efficiency, optimize resource allocation, and gain actionable intelligence from data. It finds application in medical diagnoses, credit risk assessment, image recognition, fraud detection, and customer segmentation, to name just a few.
Key Components of Classification: Data, Labels, and Features
Data: At the core of classification lies the data that builds the basis of decision-making. The data can be of various forms, such as text, images, or numerical values.
Labels: The class labels enable us to identify and separate distinct categories into which the data points are grouped. For example, in a spam email classification task, the class labels could be “spam” or “not spam.”
Features: Features are the measurable characteristics or attributes of the input data that help distinguish between different classes. For instance, in an image classification task, features could be pixel values, color histograms, or texture descriptors.
Popular classification algorithms
Decision Trees:
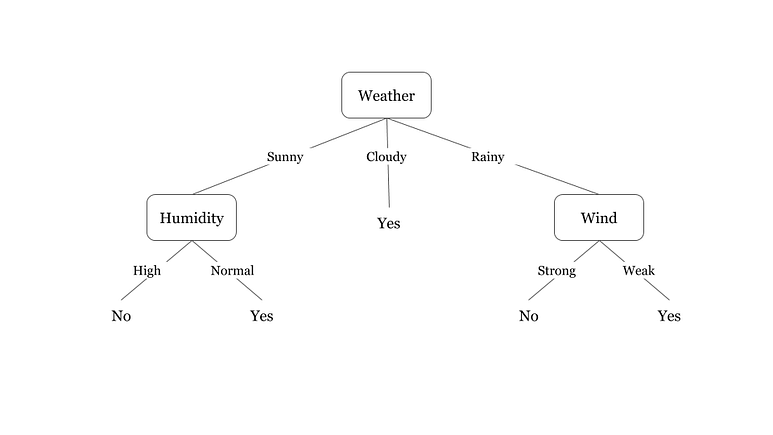
Decision trees are a form of classifying method that reflects the decision-making process of humans. It can be represented as a tree-like structure, where each leaf node represents a class label or a final judgment, and each inside node indicates a decision based on a specific trait. Real-world uses for decision trees include fraud detection, consumer segmentation, credit risk assessment, and medical diagnosis.
Naïve Bayes:
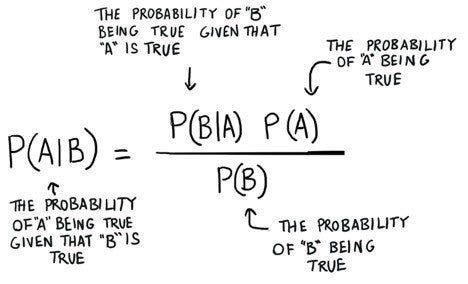
Naïve Bayes is a classification algorithm based on Bayes’ theorem and the assumption of feature independence. Despite its simplicity, Naïve Bayes has proven to be effective in various real-world applications. The algorithm gives us the probability of a data point belonging to each class by multiplying the probabilities of its features given to each class. Naïve Bayes finds applications in text classification, medical diagnosis, news categorization, and recommendation systems for efficient and accurate decision-making.
Random Forest:
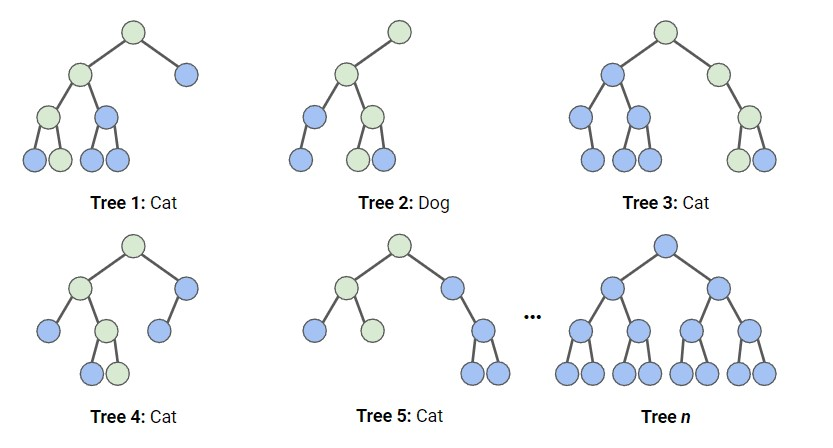
Random Forest is an ensemble learning method that combines multiple decision trees to make accurate predictions. Each decision tree is trained on a random subset of the training data, and at each split, a random subset of features is considered. To make predictions, the Random Forest aggregates the predictions of all individual trees and selects the majority class as the final prediction. Random Forest is applied in finance for credit scoring, and fraud detection, and in healthcare for disease prediction, diagnosis, and identifying important medical features.
Assessing Classification Performance: Unveiling Evaluation Metrics

Common Evaluation metrics:
When evaluating the performance of classification models, it’s crucial to understand and utilize appropriate evaluation metrics. Some commonly used evaluation metrics:
Accuracy: It is the measure of the overall correctness of predictions by calculating the ratio of correctly classified instances to the total number of instances.
Precision: It focuses on the proportion of correctly predicted positive instances out of all instances predicted as positive.
Recall: It calculates the proportion of correctly predicted positive instances out of all actual positive instances.
F1 Score: The F1 score combines both precision and recall into a single metric. It considers both false positives and false negatives.
Specificity: It measures the proportion of correctly predicted negative instances out of all actual negative instances.
Tailoring Metrics to the Task: Choosing the Appropriate Metric
Selecting the correct evaluation metric for classification tasks is crucial for accurate assessment. We have to consider the problem domain, class imbalance, cost implications, stakeholder perspectives, and trade-offs between metrics.
For example, in healthcare, high recall might be crucial for accurately identifying positive cases. Imbalanced datasets require metrics like precision, recall, or F1 score to capture performance accurately. Cost implications help determine which type of error is more significant. Stakeholder perspectives and task requirements also play a role in metric selection.
By carefully considering these factors, you can choose a metric that aligns with the task at hand and ensure a comprehensive evaluation of the classification model.
Unravelling Classifier Decisions: Interpreting and Understanding
The Significance of Classifier Decisions:
In the field of Machine Learning, interpreting the decisions made by classifiers holds a lot of importance. It goes beyond merely obtaining accurate predictions and delves into understanding why and how those decisions are reached. Here is why interpreting classifier decisions is essential:
Transparency and Trust: interpreting classifier decisions creates transparency, allowing users and stakeholders to understand the underlying factors influencing predictions. It also creates a sense of trust in the decision-making process.
Accountability and Fairness: By understanding classifier decisions, it becomes possible to identify potential biases in the model’s predictions. It allows us to rectify any unfairness or biases in the model predictions, ensuring ethical outcomes.
Domain-Specific Insights: Interpreting classifier decisions provides valuable and useful domain-specific insights. These insights can be utilized to improve processes and improve decision-making.
Interpretability Techniques
Interpreting classifier decisions involves using various techniques that provide valuable insights into how the model makes predictions. Some commonly used interpretability techniques:
Feature Importance
Decision Boundaries
Rule Extraction
Model Dissection
These interpretability techniques allow us to unravel the underlying mechanisms driving classifier decisions, providing valuable insights into the model's behavior.
Unveiling Potential Biases and Limitations in Classifier Decisions:

Biased Training Data: There is a high risk of classifiers being trained with biased data, which makes it vital for us to check for biases in the data used to train classifiers.
Unfair Outcomes: Also we need to study the predictions carefully before making any conclusions and assess if certain groups are being treated unfairly in the predictions.
Hidden Factors: Consider if there are important factors not accounted for in the classifier's decisions.
Ethical Concerns: Reflect on the ethical implications of the predictions and address any concerns.
By actively addressing biases, promoting fairness, considering hidden factors, maintaining ethical awareness, and acknowledging the limits of our understanding, we can make significant strides in improving the reliability, fairness, and ethical alignment of classifier decisions, fostering transparency, accountability, and trust in machine learning outcomes.
Conclusion
So to recap, we covered the basics of classification in supervised learning. We learned about its importance and practical uses, explored popular algorithms, and discussed evaluation metrics and techniques to handle imbalanced data. We also highlighted the significance of interpreting classifier decisions and considering biases and ethics.
I sincerely appreciate the time you invested in reading this blog article if you have made it this far. I’m delighted to continue sharing my ideas and knowledge in future blog posts, and I appreciate having you as a reader. Thank you for your support, and I look forward to our future learning adventures together.